
AWS Big Data Study Notes – EMR and Redshift

This is the cheat sheet on AWS EMR and AWS Redshift.
AWS EMR
Storage and File Systems
- HDFS: prefix with
hdfs ://(or no prefix). HDFS is a distributed, scalable, and portable file system for Hadoop. An advantage of HDFS is data awareness between the Hadoop cluster nodes managing the clusters and the Hadoop cluster nodes managing the individual steps. HDFS is used by the master and core nodes. One advantage is that it’s fast; a disadvantage is that its ephemeral storage which is reclaimed when the cluster ends. It’s best used for caching the results produced by intermediate job-flow steps. - EMRFS: prefix with s3:// EMRFS is an implementation of the Hadoop file system used for reading and writing regular files from Amazon EMR directly to Amazon S3. EMRFS provides the convenience of storing persistent data in S3 for use with Hadoop while also providing features like S3 server-side encryption, read-after-write consistency, and list consistency.
- Local file system: The local file system refers to a locally connected disk. When a Hadoop cluster is created, each node is created from an EC2 instance that comes with a preconfigured block of preattached disk storage called an instance store. Data on instance store volumes persists only during the life of its EC2 instance. Instance store volumes are ideal for storing temporary data that is continually changing, such as buffers, caches, scratch data, and other temporary content.
Node Types in Cluster
Cluster: a collection of EC2 instances. Each instance in the cluster is called a node. The node has the following types
Master node: A node that manages the cluster by running software components to coordinate the distribution of data and tasks among other nodes for processing. The master node tracks the status of tasks and monitors the health of the cluster. Every cluster has a master node, and it’s possible to create a single-node cluster with only the master node.- Core node: A node with software components that run tasks and store data in the Hadoop Distributed File System (HDFS) on your cluster. Multi-node clusters have at least one core node.
- Task node: A node with software components that only runs tasks and does not store data in HDFS. Task nodes are optional.
Hadoop Ecosystem on EMR
- HUE – graphic user interface acts as front end application on EMR cluster to interact with other applications on EMR
- Flink – a streaming dataflow engine that you can use to run real-time stream processing on high-throughput data sources
- Phoenix – use standard SQL queries and JDBC APIs to work with an Apache HBase backing store for OLTP and operational analytics
- Presto – a fast SQL query engine designed for interactive analytic queries over large datasets from multiple sources
- Pig – use SQL-like (Pig Latin) commands that runs on top of Hadoop to transform large data sets without having to write complex code and converts those commands into Tez jobs based on directed acyclic graphs (DAGs) or MapReduce programs
- Tez – create a complex directed acyclic graph (DAG) of tasks for processing data
- Hive – use an SQL-like language called Hive QL (query language) that abstracts programming models and supports typical data warehouse interactions
- HBase – run on top of HDFS to provide non-relational database capabilities
- HCatalog – access Hive metastore tables within Pig, Spark SQL, and/or custom MapReduce applications. HCatalog has a REST interface and command line client that allows you to create tables or do other operations
- Zookeeper – a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services
- Jupyter Notebook -create and share documents that contain live code, equations, visualizations, and narrative text. Two options to work with Jupyter notebooks: EMR Notebook, JupyterHub
- Ganglia – monitor clusters and grids while minimizing the impact on their performance
- Livy – enables interaction over a REST interface with an EMR cluster running Spark
- Spark – a powerful open-source unified analytics engine with micro-batching but can guarantee only-once-delivery if configured. Four modules: MLlib, SparkSQL, Spark Streaming, and GraphX. Don’t use it for batch processing or multi-user reporting with many concurrent requests.
- Mahout – a machine learning library with tools for clustering, classification, and several types of recommenders, including tools to calculate most-similar items or build item recommendations for users
- MXNet – an acceleration library designed for building neural networks and other deep learning applications
- TensorFlow – an open-source symbolic math library for machine intelligence and deep learning applications
- Oozie – manage and coordinate Hadoop jobs
- Sqoop – a tool for transferring data between Amazon S3, Hadoop, HDFS, and RDBMS databases
Please review more details in Apache Hadoop Ecosystem Cheat Sheet
Security
- IAM
- IAM policies allow or deny permissions for IAM users and groups
- IAM roles for EMRFS requests to Amazon S3
- EMR service role, instance profile, and service-linked role to access other AWS services
- Data encryption
- Data at rest
- For EMRFS on S3 – server-side (SSE-S3, SSE-KMS) or client-side (CSE-KMS, CSE-C) encryption
- For local disk (cluster nodes EC2 instance store volumes attached EBS) – open-source HDFS encryption and Linux Unified Key System (LUKS) encryption
- Data in transit
- Between S3 and cluster nodes – TLS
- Open source encryption –
- Hadoop MapReduce Encrypted Shuffle uses TLS, SASL (secure Hadoop RPC set to privacy), AES256 (HDFS data block data transfer)
- HBase: when Kerberos is enabled, the
hbase.rpc.protectionproperty is set toprivacyfor encrypted communication - Presto: SSL/TLS
- Tez: TLS
- Spark: AES-256 cipher for internal RPC communication between Spark components, SSL for HTTP protocol communication with user interfaces
- Data at rest
AWS Redshift
- Fast, fully managed the data warehouse
- PostgreSQL, Columnar storage engine, Massively Parallel Processing(MPP), OLAP functions
- Wrapped with other AWS services: S3, KMS, IAM, VPC, SWF, CloudWatch
- Analyze data with standard SQL and existing BI tools
Architecture
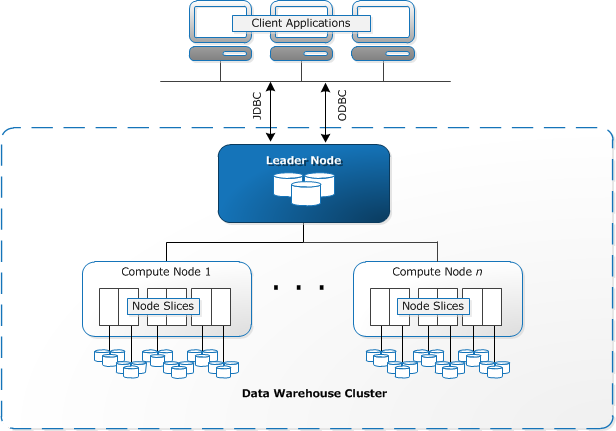
- Client Applications: ETL Tools, OLAP/BI applications
- Cluster is composed of one or more compute nodes
- Leader Node: SQL endpoint, metadata, coordinates query execution
- Compute Node: columnar storage of data, operate the work (MPP query, load/unload/backup/restore via S3/EMR/DynamoDB/SSH)
- Node Slices: each slice is allocated a portion of the node’s memory and disk space, where it processes a portion of the workload assigned to the node.
- Performance
- Massively Parallel Processing(MPP)
- Cross all compute nodes processing
- DISTSTYLE: AUTO, EVEN, KEY(DISTKEY), ALL
- AUTO: optimal distribution style based on the size of the table data e.g. ALL->EVEN
- EVEN: a table does not participate in joins
- KEY: the rows are distributed according to the values in one column e.g. joining key
- ALL: distribute to every node
- Loading data files: compression (e.g. gzip, lzop,bzip2), primary key (optimizer unique) and manifest files (JSON format to load exactly you want)
- Columnar data storage
- organizes data by column
- rapidly filter out a large subset of data blocks with sort key
- Data compression
- load data with COPY command to apply automatic compression.
- perform a compression analysis without loading data or changing the compression on a table with ANALYZE COMPRESSION
- Massively Parallel Processing(MPP)
Cluster
- Set of nodes – One leader node + One or more compute nodes
- Dense storage (DS) node types are storage optimized. The dense compute (DC) node types are compute optimized.
- One database and one superuser
- Manage cluster: modify, resize, delete and reboot
- Enhanced VPC Routing
- Force all COPY and UNLOAD traffic between cluster and data repository through VPC
- All standard VPC features
- Use VPC flow logs to monitor COPY and UNLOAD traffic
- Parameter group: apply all databases in the cluster
- Use workload management (WLM) to define the number of query queues that are available, and how queries are routed to those queues for processing. WLM is part of parameter group configuration
- Snapshots: point-in-time backups of a cluster
- Automated and manual. Redshift stores these snapshots internally in S3 by using an encrypted Secure Sockets Layer (SSL) connection
- Automatically takes incremental snapshots that track changes to the cluster since the previous automated snapshot
- A snapshot schedule is a set of schedule rules
- Exclude tables from snapshots: create a no-backup table, include the BACKUP NO parameter
- Auto copy snapshots from the source region to the destination region:
If you want to copy snapshots for AWS KMS-encrypted clusters to another region, you must create a grant for Redshift to use AWS KMS customer master key (CMK) in the destination region. Then you must select that grant when you enable copying of snapshots in the source region - Sharing snapshots: share an existing manual snapshot with other AWS customer accounts by authorizing access to the snapshot
- Monitor cluster performance: CloudWatch metrics and Query/Load performance data
- Events: Redshift tracks events and retains information about them for a period of several weeks in your AWS account
- Redshift logs: connections (connection log) and user activities (user log and user activity log) in the database
Security
- Cluster management: IAM user, role and policy
- Cluster connectivity: EC2 or VPC Security
- Database access
- Permission on database objects: CREATE USER, CREATE GROUP, GRANT, REVOKE
- Database encryption: KMS, HSM
- Data In Transit
- SQL clients to the cluster: SSL
- Load data file: server (SSE-S3) or client-side encryption
- COPY/UNLOAD/Backup/Restore: Hardware accelerated SSL
Notes List
- How to Pass AWS Certified Big Data SpecialtyAWS Big Data Study Notes – AWS Kinesis
- AWS Big Data Study Notes – EMR and Redshift
- AWS Big Data Study Notes – AWS Machine Learning and IoT
- AWS Big Data Study Notes – AWS QuickSight, Athena, Glue, and ES
- AWS Big Data Study Notes – AWS DynamoDB, S3 and SQS
- AWS Kinesis Data Streams vs. Kinesis Data Firehose
- Streaming Platforms: Apache Kafka vs. AWS Kinesis
- When Should Use Amazon DynamoDB Accelerator (AWS DAX)?
- Data Storage for Big Data: Aurora, Redshift or Hadoop?
- Apache Hadoop Ecosystem Cheat Sheet



